
我們的研究以二個主題為主,一是多核心系統層級設計和二是利用機器學習理論到電路測試和偵錯上,以下為各主題簡介︰
DNN加速器系統平台
人工智慧是目前最熱門的產業,為了處理人工智慧中深度學習網路的複雜運算以及大量訓練資料, 世界各大企業和研究機構紛紛投入資金人力研發各種加速AI運算的架構,包括紐約大學的Neuflow、 Intel收購的Movidius的Myriad、中國科學院的大電腦和視電腦、 麻省理工學院的Eyeriss、 Google的Tensor Processing Unit、Nvidia的NVDLA等。 上述案例顯示了深度學習加速計算領域的快速發展,必須設計加速器架構以符合產業應用的耗能和效能需求。 然而深度學習硬體加速器的開發有許多技術難題,需從複雜的深度學習軟體(如Tensorflow,Caffe2,Mxnet)開始, 剖析效能瓶頸,然後進行軟硬體分割、 軟硬體介面設計與加速器設計。開發過程中需要調整深度學習網路中大量的設計參數, 以根據應用程式對效能、功率甚至可靠度等規格進行最佳化。 若軟硬體開發缺乏溝通,將導致硬體團隊難以提早進行系統測試,也無法在開發初期進行軟硬體系統設計參數的調整, 減損產品開發的速度與最終效能。為了降低系統開發門檻, 本計畫將與資通所合作開發一個針對深度學習加速器設計的虛擬平台及效能、功率與可靠度的分析與最佳化方法。
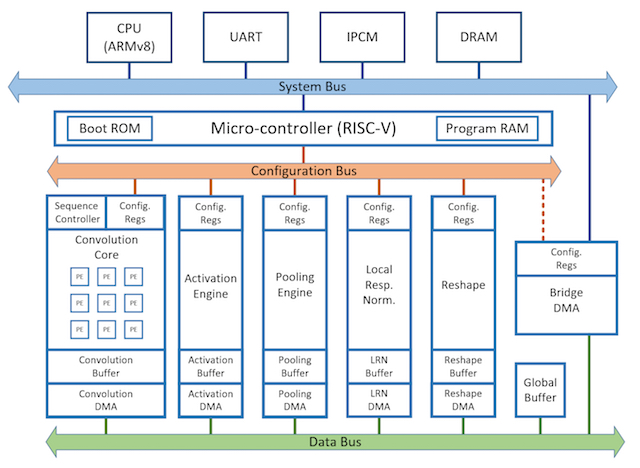
核心系統平台
利用大量平行化程式,多核心系統具有較有效利用功率的特性,但在系統設計上有許多不確定的因素,如核心數、頻寛、計算功能等都需要決定,但目前除利用架構模擬器外(必需客制化且核心數有限),只能依靠設計人員的經驗,我們的系統平台,期望可以使用標準介面,達成各元件可相互取代,快速測試各種狀態,以完成一電子系統的架構藍圖,提供設計人員可靠的參考資訊。目前我們已完成多核CPU叢集 (cluster),晶片網路 (Network-on-Chip, NoC) ,外部記憶體等元件,可依需求加以組合變化。利用建制的系統函式庫,我們已可以執行各種平行軟體如物件追縱, JPEG壓縮,三維圖形管線rasterization等。以下我們列出重要的特點︰
- 使用標準介面如SystemC, TLM 和 OCP等
- 高效能系統函式庫 (message passing interface and pthread)
- 所有元件皆有RTL可合成模型 (以建立準確的時序和功率消秏)
- 可使用任意處理器 (RISC-V, MIPS and OpenRisc)
- 和DRAMSim2整合以建立正確記憶體模型
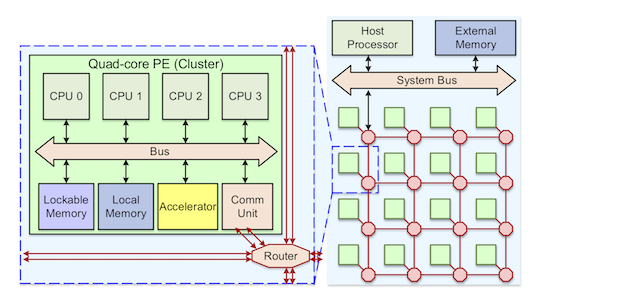
以這一平台為基礎,我們開發了以下的技術以支援多核心下遇到的難題,如模擬速度過慢,除錯困難,軟硬體介面效能不彰等問題︰
- 快速晶片上網路模擬器
傳統上,我們必須建立以週期為準的晶片上網路模擬器,但在worm-hole轉換電路上,這樣的模擬器通常複雜又慢。為處理這一問題,我們提出以時序計算為基礎的模擬器,其加速的原理在於,晶片上網路的封包,大部分可以由簡單的公式算出到達目的地的時間,並不用每一個週期都考慮,只有少部分封包需用到電路特性如FIFO和封包干擾等,所以我們可以快速完成模擬,其加速和一SystemC的模型比較可以快達73-95倍,並有和RTL一樣的準確度。
- 高效能晶片上網路介面
一般在晶片上網路的系統內部,軟體層所可使用到的吞吐率(throughput)常常遠不及硬體設計,為解決這一問題,我們大幅改善了軟體介面程序,並把部分message passing 使用硬體實作,把系統最快頻寬提高到了約2687Mbps,和原晶片上網路速度3200Mbps相比,可達八成以上,考慮到封包大小和其他成本(如header),已經接近極速(原軟體設計僅有約150Mbps)。在設計上,只有用約19K邏輯閘。
- 高效能DRAM模擬器
利用transaction speculation方式實現event-based記憶體模型。透過一次計算多個記憶體指令,我們可以在保持原有精準度的情況下,大幅的提升模擬速度。實驗顯示最多可比現有的技術平均快146.5倍。
- Message passing APIs系統記錄器
除錯是平行系統程式最難的解決的問題之一,在程式間的溝通上,我們提出一較高抽象階層的記錄器 (有別於傳統的訊號記錄器),直接處理每一個處理器單元所產生的通訊要求,在多核心的系統平台上,已幫我們找到各種問題的原因,如FIFO overrun,晶片上網路處理多重輸入的公平性,以及一平行軟體的速度問題等。這一設計可大幅降低資料量 (為訊號記錄器的0.23%) ,且在一16核心系統上僅秏用40K邏輯閘。
- Farneback Optical Flow平行加速器
Farneback Optical Flow演算法可估算出每個像素在兩個time frame的位移,可用於精確的物件追蹤和各種動作預測,但其複雜度高,不易即時找出結果,我們利用高階合成設計不同的平行和管線架構以及記憶體管理,可以達成在一個Zynq FPGA板上將演算法有效從50ms降低到6ms,且同時大幅減少記憶體資源需求。
安全性電路設計
隨著自主車和相關自動化產業的發展,系統的功能安全(Functional Safety)與可靠度(Reliability)議題也越發重要,例如車用系統晶片的, 必須從系統的角度來設計高可靠度和功能安全的特性,如果發生系統故障或失效, 可能會威脅到駕駛與乘客之生命安全並造成嚴重的後果。
分析系統層級的功能安全性和可靠性,必須透過完整的功能錯誤模擬(functional fault simulation)得知不同的錯誤(fault)會對系統有什麼樣的影響。 一般而言,分析錯誤模型的方法先進行無錯誤(fault-free)模型,得到特定測試輸入下, 電路的暫存器以及記憶體狀態改變的位置以及時間。有了狀態改變的位置和時間, 就能夠針對這些暫存器和記憶體注入錯誤,並且觀察系統在有錯誤情況下的輸出。 然而隨著系統晶片的複雜度與規模提升,大型系統晶片可能含有數萬個暫存器或記憶體位置改變狀態, 不可能將所有可能的位置和時間都進行錯誤注入和模擬。 此外,gate-level/RTL錯誤模擬速度可能逐漸無法應付電路測試的需求,特別處理大量模擬時脈週期的測試向量 ,因此一個快速且有效率的錯誤模擬對於分析系統層級的功能安全性和可靠性是必須的, 我們在計畫中預計使用上述在系統平台的經驗,實作各式相對應的設計工具和流程。
應用機器學習理論到電路測試和偵錯
在目前測試程序日益複雜,再加上製程變異趨大的情形下,我們有必要開發新的測試方法和觀念,特別是利用應用機器學習理論處理和分析大量測試資料,以有效提昇良率。
- 應用機器學習理論到電路測試和偵錯
在目前測試程序日益複雜,再加上製程變異趨大的情形下,我們有必要開發新的測試方法和觀念,特別是利用應用機器學習理論處理和分析大量測試資料,以有效提昇良率。
- 後矽製程變異量測以及增進電路良率電壓調整方法
我們提出一MLE量測方法,可以得到最可能的電路上邏輯閘和訊號線的延遲,和過去方法相較,我們不需假設電路缺陷的特性和模型,所以我們可以得到實際電路缺陷延遲數值,並推算系統性變異,在實驗結果中我們可得到平均0.848的相關係數,在不使用額外電路的情形下,是目前最準確的方法。 以上述的後矽製程變異量測方法為基礎,我們進一步提出微調電路電壓架構,在電路延遲測試未通過時,我們把量測結果轉換成一組 Boolean Satifiability公式,並開發一求解過程,找到電路調整最佳解,由於使用微調電壓,修復的電路可使用比設計功率僅高10%以內,達到提高良率至八成以上(原良率約三成)。
- 多重測試頻率SVM 晶片分類
上述電路良率電壓調整方法,雖良率大幅提高,但相對的測試代價和計算成本過高,實際應用會有困難,為改善這一問題,我們提出了一使用多重測試頻率的結果來進行晶片分類,我們發現只要使用二個測試頻率(測試成本僅約原方法的4%以下),即可達到修復86%至118%的晶片良率,顯示SVM模型可有效代表晶片各種效能變異的結果,我們認為這一結果可能應用到更多晶片的測試和分析上,對現在實際遇到高複雜度以及大量的測試資料有很大的幫助。
- 使用加壓測試與支持向量機以縮減晶片系統測試之成本
因為晶片常用的結構化測試(ATPG-based),是以不同於晶片正常操作的模式進行測試,所以對於系統運作下,各功能互動的情形並無法完全考慮,故通常還需要進行全系統軟體測試來減少產品的不良率。然而,系統測試的成本較高,例如需要更長的測試時間與特製的搭載基板;並且,系統測試所用的軟體程式不一定有效,在選用上,常與 IC 設計工程師對於功能上的認知有所出入。為了減少對系統測試的依賴,我們可以使用加壓結構化測試(stressed structural tests),並在結果中尋找適合的特徵(features),將系統測試的結果(通過/不通過)作為類別標籤(class labels),透過機器學習演算法來訓練分類器。有了適合的特徵,我們就能使用較少量的加壓測試去部分替代高成本的系統測試,以增加系統測試的整體吞吐率。我們提出了一個有效的特徵自動萃取方法,大幅提高分辦率,同時我們利用支持向量機(SVM)的特點,設計了一個可以調動系統測試比率的方法,提高測試的信心度。
- 後矽製程電路老化預測流程
電路老化測試常使用升高的溫度或電源電壓進行Burn-in,但過程昂貴並且可能會損壞產品。我們知道NBTI電路老化可以由電路的使用狀況(signal stress)以及電路本身的變異程度來預測,在我們提出的方法,由實驗結果可以得到非常接近預測的老化年齡(<5%的錯誤)。
