
Low-Overhead Content-Adaptive Spatial Scalability for Scalable Video Coding
Chia-Wen Lin, Senior Member, IEEE, Chia-Ming Tsai, and Po-Chun Chen
Abstract
To support spatial scalability, the scalable extension of H.264/AVC (SVC) uses video cropping or uniform scaling to downscale the original higher-resolution (HR) sequence to a lower resolution (LR) sequence. Both operations, however, will cause critical visual information loss in the retargeted frames. The content-adaptive spatial scalability SVC coders (CASS-SVC) use non-homogeneous scaling to avoid critical information loss, which, however, requires to send additional side information to signal the decoder, thereby degrading coding efficiency significantly. To address the problem, we propose a low-overhead CASS-SVC coder consisting of three main modules: a mosaic-guided video retargeter, a side-information coder, and a non-homogeneous inter-layer predictive coder. The proposed video retargeting scheme first constructs a panoramic mosaic for each video shot to obtain a compact shot-level global scaling map which is then used to derive the scaling maps of individual frames in the shot at both the encoder and decoder. The side information required for the non-homogeneous scaling, including the global scaling maps and the spatial corresponding positions of individual frames to the panoramic mosaic, are then efficiently coded by the side-information coder. The non-homogeneous interlayer prediction coding tools are used to provide good predictions to reduce the bitrates for coding the HR frames. Our experimental results demonstrate that, compared to existing CASS-SVC coders, our method cannot only well preserve subjective quality of important content in the LR sequence, but also significantly improves the coding efficiency of HR sequence.
Key words: Video adaptation, video retargeting, spatial scalability, scalable video coding, inter-layer prediction.
Experimental Results
Due to the paper length limit, we show more experimental comparision results in the following figures.
| Original Video | Uniform Scaling | Krahenbul et al. | Wang et al. | Our method. |
| Fig. 1. Subjective quality comparison of the proposed method with uniform scaling, the retargeting scheme proposed by Krahenbuhl et al. [9], and the retargeting scheme without cropping operator proposed by Wang et al. [10]. | ||||
To verify the performance of the proposed non-homogeneous inter-layer predictive coder under different quantization parameter (QP) settings, we designed two set of QP settings. Fig. 2 and Fig. 3 compare the rate-distortion performances of the HR-layer video between our method and the conventional SVC using the two QP settings, respectively. Based on the proposed EL-BL mapping matrix, the non-homogeneous inter-layer prediction tools provide good prediction quality.
(a) |
(b) |
(c) |
(d) |
(e) |
(f) |
Fig. 2. Rate-distortion performance comparisons between the proposed framework and the conventional SVC for the high-resolution layer video.The GOP size is set to 16, and the QP is set to 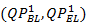 = {(32,36), (28,32), (24,28), (20,24)} for (a) Die Hard 4.0; (b) How; (c) Cape No.7 - Concert; (d) Parkscene; (e) Sunflower; and (f) Traffic. = {(32,36), (28,32), (24,28), (20,24)} for (a) Die Hard 4.0; (b) How; (c) Cape No.7 - Concert; (d) Parkscene; (e) Sunflower; and (f) Traffic. |
|
(a) |
(b) |
(c) |
(d) |
(e) |
(f) |
Fig. 3. Rate-distortion performance comparisons between the proposed framework and the conventional SVC for the high-resolution layer video.The GOP size is set to 16, and the QP is set to 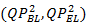 = {(24,36), (24,32), (24,28), (24,24)} for (a) Die Hard 4.0; (b) How; (c) Cape No.7 - Concert; (d) Parkscene; (e) Sunflower; and (f) Traffic. = {(24,36), (24,32), (24,28), (24,24)} for (a) Die Hard 4.0; (b) How; (c) Cape No.7 - Concert; (d) Parkscene; (e) Sunflower; and (f) Traffic. |
|
To evaluate the impact of the inaccuracy of automatic segmentation on our retargeting method, we disabled the user-scribbled refinement and used the automatic segmentation tool only to obtain the segmentation mask and use the mask to derive the global scaling map for retargeting. Figs. 4.1~ 4.3 show three retargeting examples for three shot-level mosaics by using the automatic segmentation tool and the semi-automatic segmentation tool. The results show that, although the automatic segmentation tool tends to result in over-segmented regions, our retargeting method is not very sensitive to such kind of over-segmentation. The main reason is that even if a region is over-segmented into several sub-regions, the energy values within these sub-regions which belong to the same region are usually still close due to their similar energy values and the spatial smoothness constraints imposed. As a result, the derived scaling factor values of these sub-regions will still be similar.
| Shot-Level Panoramic Mosaic (a) |
Original Frame (b) |
| Mask obtained by automatic segmentation (c) |
Retargeted Frame using (c) (d) |
| Mask obtained by user-scribbled refinement (e) |
Retargeted Frame using (f) (f) |
| Fig. 4.1. A video retargeting example using automatic segmentation and semi-automatic segmentation. | |
| Shot-Level Panoramic Mosaic (a) |
Original Frame (b) |
| Mask obtained by automatic segmentation (c) |
Retargeted Frame using (c) (d) |
| Mask obtained by user-scribbled refinement (e) |
Retargeted Frame using (f) (f) |
| Fig. 4.2. A video retargeting example using automatic segmentation and semi-automatic segmentation. | |
| Shot-Level Panoramic Mosaic (a) |
Original Frame (b) |
| Mask obtained by automatic segmentation (c) |
Retargeted Frame using (c) (d) |
| Mask obtained by user-scribbled refinement (e) |
Retargeted Frame using (f) (f) |
| Fig. 4.3. A video retargeting example using automatic segmentation and semi-automatic segmentation. | |
We conducted subjective tests to evaluate the visual performance of the proposed CASS-SVC and the conventional SVC. In our experiments, we invited 10 subjects to participate in the subjective tests. None of the subjects had knowledge about the algorithm implementations. Four test sequences are coded using hierarchical B-picture prediction structure with two spatial resolutions with a GOP size of 16. Each HR video is downscaled by the uniform scaling and the proposed retargeting scheme to obtain its LR sequence. The QP for the LR and HR sequences are set to 24. When evaluating the quality of reconstructed LR sequences, the subjects were asked to answer “how well the retargeted LR sequence faithfully preserves the content of the original video” which is labeled as Q1 in Table I. When evaluating the quality of reconstructed HR sequences, subjects were asked to answer “how good the visual quality of HR sequence is” which is labeled as Q2 in Table I. Each question is scored from 5 (excellent) to 1 (poor). Table I shows the result of the subjective tests. The experimental results show that the proposed CASS-SVC achieves better performance in preserving important visual content in the LR video and subjective visual quality in the HR video, compared with the uniform scaling method. Note, although the PSNR qualities of HR videos reconstructed by the proposed CASS-SVC is slightly lower than that reconstructed by traditional SVC, the proposed method achieves better subjective quality compared to SVC. This is because, similar to ROI-based coding, CASS-SVC better preserves the salient regions in the LR video, thereby achieving better visual quality perceptually after inter-layer prediction.
Table I
Subjective quality comparisons between the uniform scaling and the proposed CASS-SVC for four test sequences.
DieHard 4 How Kimono ParkScene Upstairs Uniform Scaling Proposed Uniform Scaling Proposed Uniform Scaling Proposed Uniform Scaling Proposed Uniform Scaling Proposed Q1 3.9 3.9 4 4.1 3.7 4.2 3.5 4.3 3 3.9 Q2 3.6 3.9 4 4.3 4.2 4.1 3.9 4.1 3.6 3.4
References
P. Krahenbuhl, M. Lang, A. Hornung, and M. Gross, “A system for retargeting of streaming video,” ACM Trans. Graphics, vol. 28, no. 5, 2009. Y.-S. Wang, J.-H. Hsiao, O. Sorkine, and T.-Y. Lee, “Scalable and coherent video resizing with per-frame optimization,” ACM Trans. Graphics, vol. 30, no. 4, 2011. C.-M. Tsai, T.-C. Yen, and C.-W. Lin, "Mosaic-guided video retargeting for video adaptation," in Proc. Conference on Applications of Digital Image Processing XXXIV, SPIE Optics+Photonics 2011, Aug. 2011, San Diego, CA, USA. H. Schwarz, D. Marpe, and T. Wiegand, “Overview of the scalable extension of the H.264/MPEG-4 AVC video coding standard,” IEEE Trans. Circuits. Syst. Video Technol., vol. 17, no. 9, pp. 1103–1120, Sept. 2007. Y. Wang, N. Stefanoski, M. Lang, A. Hornung, A. Smolic, and M. Gross, “Extending SVC by content-adaptive spatial scalability,” in Proc. Int. Conf. Image Process., Sept. 2011, pp. 3493–3496, Brussels, Belgium. T.-C. Yen, C.-M. Tsai, and C.-W. Lin, “Maintaining temporal coherence in video retargeting using mosaic-guided scaling,” IEEE Trans. Image Process., vol. 20, no. 8, pp. 2339–2351, Aug. 2011.