eCNN: A Block-Based and Highly-Parallel CNN Accelerator for Edge Inference
Chao-Tsung Huang, Yu-Chun Ding, Huan-Ching Wang, Chi-Wen
Weng, Kai-Ping Lin, Li-Wei Wang, Li-De Chen
Department of Electrical Engineering
National Tsing Hua University, Taiwan, R.O.C.
|
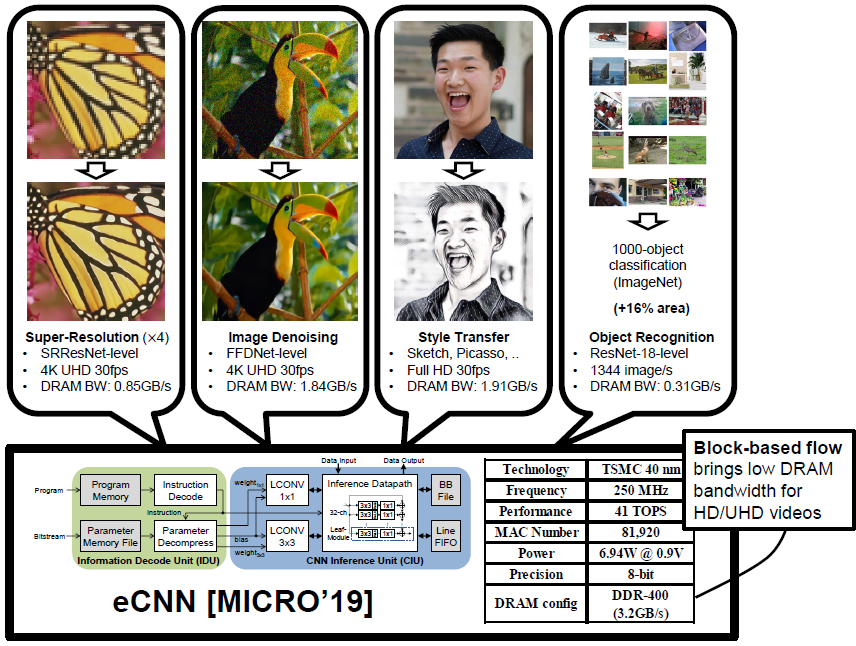
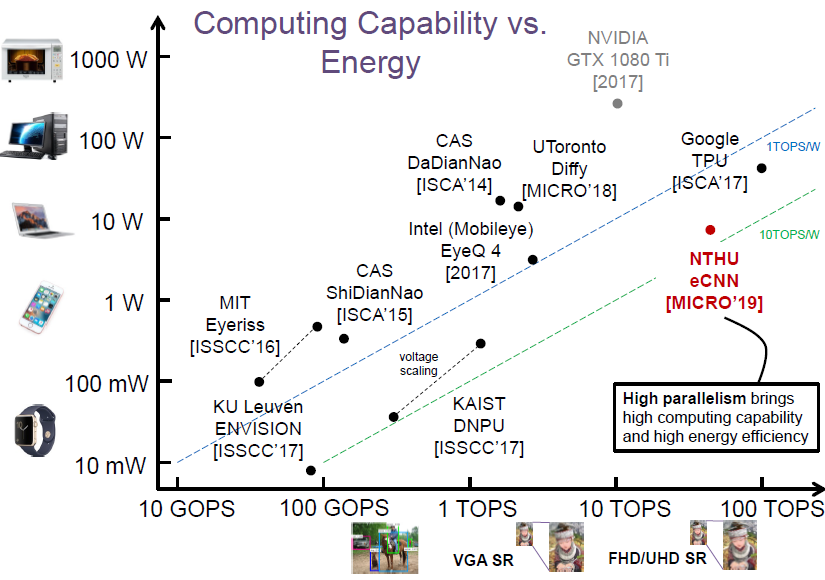
Abstract Convolutional neural networks (CNNs) have recently demonstrated superior quality for computational imaging applications. Therefore, they have great potential to revolutionize the image pipelines on cameras and displays. However, it is difficult for conventional CNN accelerators to support ultra-high-resolution videos at the edge due to their considerable DRAM bandwidth and power consumption. Therefore, finding a further memory- and computation-efficient microarchitecture is crucial to speed up this coming revolution. In this paper, we approach this goal by considering the inference flow, network model, instruction set, and processor design jointly to optimize hardware performance and image quality. We apply a block-based inference flow which can eliminate all the DRAM bandwidth for feature maps and accordingly propose a hardware-oriented network model, ERNet, to optimize image quality based on hardware constraints. Then we devise a coarse-grained instruction set architecture, FBISA, to support power-hungry convolution by massive parallelism. Finally,we implement an embedded processor—eCNN—which accommodates to ERNet and FBISA with a flexible processing architecture. Layout results show that it can support high-quality ERNets for super-resolution and denoising at up to 4K Ultra-HD 30 fps while using only DDR-400 and consuming 6.94W on average. By comparison, the state-of-the-art Diffy uses dual-channel DDR3-2133 and consumes 54.3W to support lower-quality VDSR at Full HD 30 fps. Lastly, we will also present application examples of high-performance style transfer and object recognition to demonstrate the flexibility of eCNN. Publication "eCNN: A
Block-Based and Highly-Parallel CNN Accelerator for Edge
Inference," in IEEE/ACM International Symposium on
Microarchitecture (MICRO), 2019. Extension: C.-T. Huang, "ERNet: Hardware-Oriented CNN Models for Computational Imaging Using Block-Based Inference," in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020. [arXiv:1910.05787] C.-W. Weng, C.-T. Huang, "A Quality-Oriented Reconfigurable Convolution Engine Using Cross-Shaped Sparse Kernels for Highly-Parallel CNN Acceleration", in IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), 2021. |
|
Lightning Talk Video (1.5 minutes)
Performance
Computing Capability
|
|
Acknowledgement This work was supported by the Ministry of Science and Technology, Taiwan, R.O.C. under Grant no. MOST 107-2218-E-007-029.
Last update on Apr 20, 2021 |